Mongo
Replica Set介绍
副本集。集群当中包含了多份数据,保证主节点挂掉了,备节点能继续提供数据服务,提供的前提就是数据需要和主节点一致 。
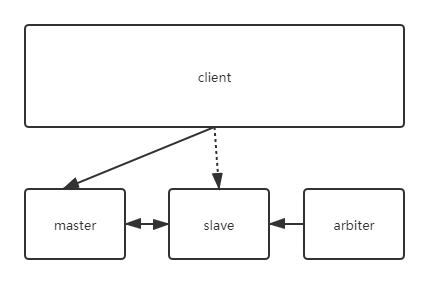
master表示主节点,slave表示备节点,arbiter表示仲裁节点。主备节点存储数据,仲裁节点不存储数据。客户端同时连接主节点与备节点,不连接仲裁节点。
搭建配置
生成keyFile
# 400权限是要保证安全性,否则mongod启动会报错 openssl rand -base64 756 > mongodb.key chmod 400 mongodb.key编写mongod.conf(3个)
#副本集的名字 replSet=gjzz #mongodb所绑定的ip地址 bind_ip=192.168.0.177编写yml
version: '3.8' services: mongo-01: image: mongo:4.2.12 environment: MONGO_INITDB_ROOT_USERNAME: root MONGO_INITDB_ROOT_PASSWORD: "gjzz2020@#" volumes: - ./mongo-01/data:/data/db - ./mongo-01/config:/etc/mongo - ./mongodb.key:/data/mongodb.key ports: - "27017:27017" command: mongod --replSet gjzz --keyFile /data/mongodb.key restart: always entrypoint: - bash - -c - | chmod 400 /data/mongodb.key chown 999:999 /data/mongodb.key exec docker-entrypoint.sh $$@配置副本集
进入docker容器
docker exec -it mongo-01 bash连接mongo
mongo -u 账号 -p 密码执行命令
> rs.initiate({ ... ... _id: "gjzz", ... ... members: [ ... ... { _id : 0, host : "192.168.0.177:27017" }, ... ... { _id : 1, host : "192.168.0.177:27018" }, ... ... { _id : 2, host : "192.168.0.177:27019" } ... ... ] ... ... }); { "ok" : 1 }
Mycat
介绍
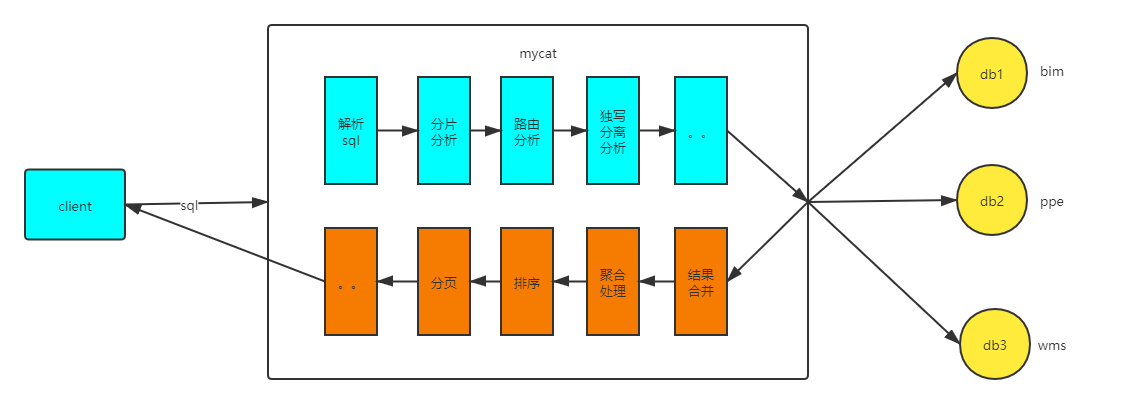
Mycat 最重要的一个动词是“拦截”,它拦截了用户发送过来的 SQL 语句,首先对 SQL
语句做了一些特定的分析:如分片分析、路由分析、读写分离分析、缓存分析等,然后将此 SQL 发
往后端的真实数据库,并将返回的结果做适当的处理,最终再返回给用户。
搭建
mysql群搭建
编写docker-conpose.yml(4个MySQL)
version: '3.8' services: mysql-01: image: mysql:5.7.21 environment: - MYSQL_ROOT_PASSWORD=123456 volumes: - ./mysql-01/config:/etc/mysql/conf.d - ./mysql-01/data:/var/lib/mysql ports: - 3301:3306 restart: always
mycat群搭建
编写docker-compose.yml(2个Mycat)
version: '3.8' services: mycat-01: image: docker.craftmake.cn/mycat:1.6.7 volumes: - ./mycat-01/config/rule.xml:/usr/local/mycat/conf/rule.xml:ro - ./mycat-01/config/server.xml:/usr/local/mycat/conf/server.xml:ro - ./mycat-01/config/schema.xml:/usr/local/mycat/conf/schema.xml:ro - ./mycat-01/logs/:/usr/local/mycat/logs ports: - 8066:8066 - 9066:9066 restart: always
注:mycat启动前先完成相关配置。
Mycat配置
server.xml配置
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mycat:server SYSTEM "server.dtd">
<mycat:server xmlns:mycat="http://io.mycat/">
<system>
</system>
<user name="cat">
<property name="cat">gjzz2020</property>
<property name="schemas">
app_base_msg,
app_pub_bim
</property>
</user>
</mycat:server>
schema.xml配置
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<!--schema-->
<schema name="app_base_msg" checkSQLschema="false" dataNode="dn_msg_1">
</schema>
<schema name="app_pub_bim" checkSQLschema="false" dataNode="dn_bim_1">
<table name="BIM_BarCodeFlow" dataNode="dn_bim_1,dn_bim_2" rule="dataRule"></table>
<table name="BIM_BarCodeMaster" dataNode="dn_bim_1,dn_bim_2" rule="dataRule"></table>
<table name="BIM_BarCodeUsed" dataNode="dn_bim_1,dn_bim_2" rule="dataRule"></table>
<table name="BIM_BarCodeRelation" dataNode="dn_bim_1,dn_bim_2" rule="dataRule"></table>
<table name="BIM_BarCodeRule" dataNode="dn_bim_1,dn_bim_2" type="global"></table>
<table name="BIM_PrintAssign" dataNode="dn_bim_1,dn_bim_2" type="global"></table>
<!--dataNode-->
<dataNode name="dn_msg_1" dataHost="host_msg_1" database="app_base_msg" />
<dataNode name="dn_bim_1" dataHost="host_bim_1" database="app_pub_bim" />
<dataNode name="dn_bim_2" dataHost="host_bim_2" database="app_pub_bim" />
<!--dataHost-->
<dataHost name="host_msg_1" maxCon="600" minCon="10" balance="1"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="wh_msg_1" url="" user="" password="">
<readHost host="rh_msg_1" url="" user="" password=""></readHost>
</writeHost>
</dataHost>
<dataHost name="host_bim_1" maxCon="600" minCon="10" balance="1"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="wh_bim_1" url="" user="" password="">
<readHost host="rh_bim_1" url="" user="" password=""></readHost>
</writeHost>
</dataHost>
<dataHost name="host_bim_2" maxCon="600" minCon="10" balance="1"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="wh_bim_2" url="" user="" password="">
<readHost host="rh_bim_2" url="" user="" password=""></readHost>
</writeHost>
</dataHost>
</mycat:schema>读写分离
主从复制
原理

修改mysql配置文件
#Master #主服务器唯一ID server-id=1 #启用二进制日志 log-bin=mysql-bin # 设置不要复制的数据库(可设置多个) binlog-ignore-db=mysql binlog-ignore-db=information_schema #设置需要复制的数据库 binlog-do-db=需要复制的主数据库名字 #设置logbin格式 binlog_format=STATEMENT #Slave #从服务器唯一ID server-id=2 #启用中继日志 relay-log=mysql-relay重启Mysql服务
主机建立账号
GRANT REPLICATION SLAVE ON *.* TO 'slave'@'%' IDENTIFIED BY 'slave';查询master状态
show master status
记录File和Position的值
执行完此步骤后不要再操作主服务器MySQL,防止主服务器状态值变化
从机执行复制命令
CHANGE MASTER TO MASTER_HOST='192.168.0.177', MASTER_PORT=3300, MASTER_USER='slave', MASTER_PASSWORD='slave', MASTER_LOG_FILE='mysql-bin.000001', MASTER_LOG_POS=438启动复制功能
start slave;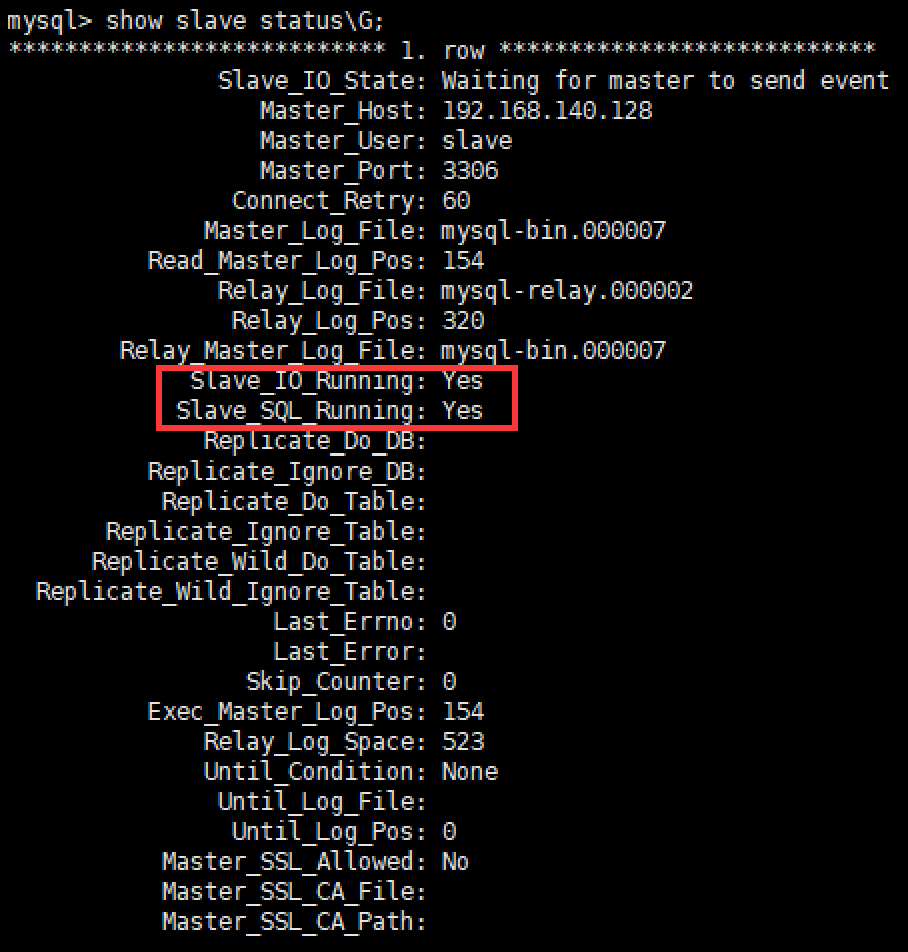
Slave_IO_Running和Slave_SQL_Running都是YES则配置成功
mycat配置
<dataHost name="host_cds_1" balance="1" writeType="0" switchType="1">
<heartbeat>select user()</heartbeat>
<writeHost host="" url="" user="" password="">
<readHost host="" url="" user="" password=""></readHost>
</writeHost>
</dataHost>
<!--
balance="0", 不开启读写分离机制,所有读操作都发送到当前可用的 writeHost 上。
balance="1",全部的 readHost 与 stand by writeHost 参与 select 语句的负载均衡。
balance="2",所有读操作都随机的在 writeHost、readhost 上分发。
balance="3",所有读请求随机的分发到 readhost 执行,writerHost 不负担读压力。
switchType="1": 1 默认值,自动切换。
-1 表示不自动切换。
2 基于 MySQL 主从同步的状态决定是否切换。
-->分表
mycat配置
schema.xml
<schema name="app_dsf_les" checkSQLschema="false" dataNode="dn_les_1">
<table name="LES_FeedRecord" dataNode="dn_les_1,dn_les_2" rule="dataRule"></table>
<table name="LES_IssueRecord" dataNode="dn_les_1,dn_les_2" rule="dataRule"></table>
<table name="LES_DeliveryRecord" dataNode="dn_les_1,dn_les_2" rule="dataRule"></table>
<table name="LES_DeliveryPlan" dataNode="dn_les_1,dn_les_2" rule="dataRule"></table>
</schema>
<dataNode name="dn_les_1" dataHost="host_les_1" database="app_dsf_les" />
<dataNode name="dn_les_2" dataHost="host_les_2" database="app_dsf_les" />
<dataHost name="host_les_1" maxCon="600" minCon="10" balance="1"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="wh_les_1" url="" user="" password="">
<readHost host="rh_les_1" url="" user="" password=""></readHost>
</writeHost>
</dataHost>
<dataHost name="host_les_2" maxCon="600" minCon="10" balance="1"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="wh_les_2" url="" user="" password="">
<readHost host="rh_les_2" url="" user="" password=""></readHost>
</writeHost>
</dataHost> rule.xml
<tableRule name="dataRule">
<rule>
<columns>createdOn</columns>
<algorithm>sharding-by-date</algorithm>
</rule>
</tableRule>
<function name="sharding-by-date" class="io.mycat.route.function.PartitionByDate">
<property name="dateFormat">yyyy-MM-dd HH:mm:ss</property>
<property name="sBeginDate">2020-01-01 00:00:00</property>
<property name="sEndDate">2020-01-14 00:00:00</property>
<property name="sPartionDay">7</property>
</function>分片规则
Rabbitmq
普通集群
介绍

- RabbitMQ代理操作所需的所有数据/状态都将跨所有节点复制。
- 该模式不会自动主从切换,且从节点只同步队列,但无法消费。
搭建
生成.erlang.cookie 用于节点间的通讯
创建yml
version: '3.8' services: rabbitmq-01: image: rabbitmq:management environment: - "RABBITMQ_DEFAULT_USER=chen" - "RABBITMQ_DEFAULT_PASS=chen" - "ES_JAVA_OPTS=-Xms512m -Xmx512m" - "RABBITMQ_NODENAME:rabbitmq01" volumes: - ./rabbitmq-01/data:/var/lib/rabbitmq - ./rabbitmq-cluster.sh:/opt/rabbitmq-cluster.sh - ./.erlang.cookie:/var/lib/rabbitmq/.erlang.cookie hostname: rabbitmq01 ports: - 5673:5672 - 15673:15672 restart: always user: root创建rabbitmq-cluster.sh
rabbitmqctl stop_app rabbitmqctl reset rabbitmqctl join_cluster rabbit@rabbitmq01 #disk存储 #rabbitmqctl join_cluster --arm rabbit@rabbitmq01 #ram存储 rabbitmqctl start_app进入从节点执行脚本
镜像集群
介绍
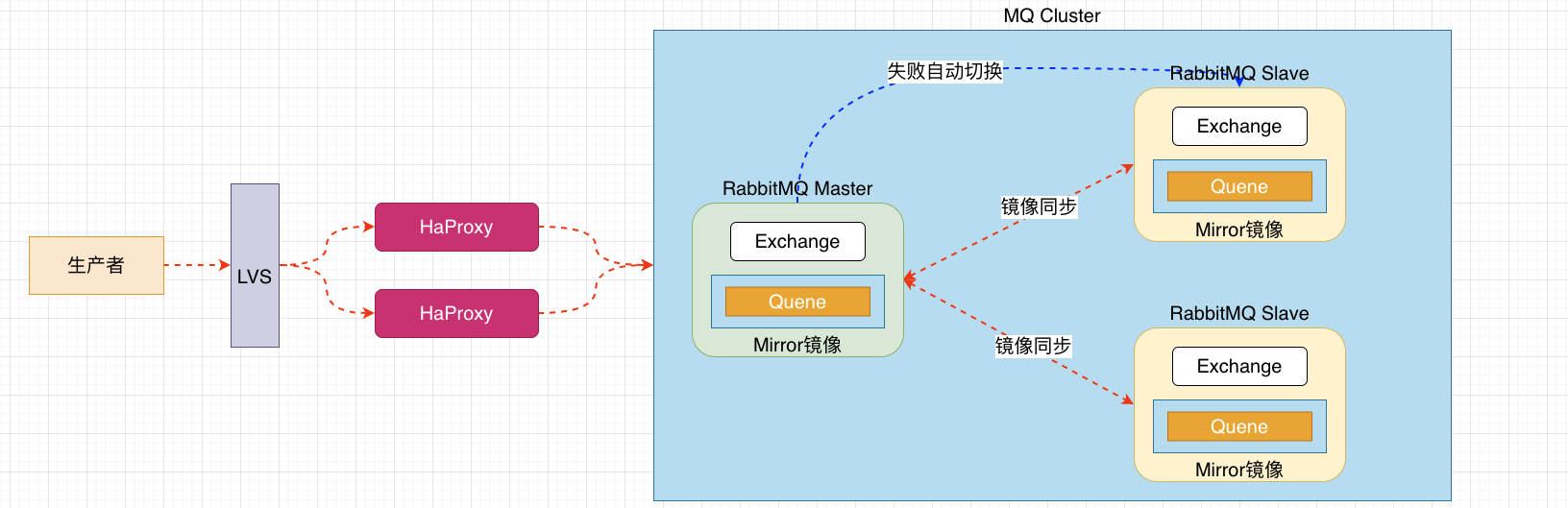
镜像队列机制就是将队列在三个节点之间设置主从关系,消息会在三个节点之间进行自动同步,且如果其中一个节点不可用,并不会导致消息丢失或服务不可用的情况,提升MQ集群的整体高可用性。
配置
# 0.策略说明
rabbitmqctl set_policy [-p <
>] [--priority <priority>] [--apply-to <apply-to>] <name> <pattern> <definition>
-p Vhost: 可选参数,针对指定vhost下的queue进行设置
Name: policy的名称
Pattern: queue的匹配模式(正则表达式)
Definition:镜像定义,包括三个部分ha-mode, ha-params, ha-sync-mode
ha-mode:指明镜像队列的模式,有效值为 all/exactly/nodes
all:表示在集群中所有的节点上进行镜像
exactly:表示在指定个数的节点上进行镜像,节点的个数由ha-params指定
nodes:表示在指定的节点上进行镜像,节点名称通过ha-params指定
ha-params:ha-mode模式需要用到的参数
ha-sync-mode:进行队列中消息的同步方式,有效值为automatic和manual
priority:可选参数,policy的优先级
# 1.查看当前策略
rabbitmqctl list_policies
# 2.添加策略
说明:策略正则表达式为 “^” 表示所有匹配所有队列名称 ^hello:匹配hello开头队列
# 3.删除策略
rabbitmqctl clear_policy ha-allRedis
Redis-Cluster集群简介及特性
采用P2P模式,完全去中心化, 集群内部的节点是相互通信的(PING-PONG机制),每个节点都是一个redis实例 。
投票容错机制: 超过半数的节点投票认为某个节点挂了,那么这个节点就挂了(fail)。
集群内置了16384个slot(哈希槽),并且把所有的物理节点映射到了这16384个slot上。Redis集群存放一个数据(key-value)时,redis会先对这个key进行crc16算法,然后得到一个结果。再把这个结果对16384进行求余,这个余数会对应[0-16383]其中一个槽,进而决定key-value存储到哪个节点中。所以一旦某个节点挂了,该节点对应的slot就无法使用,那么就会导致集群无法正常工作。
支持主从自动切换 。
只有一个db库,不支持多库。
搭建
编写redis.conf(6个)
# 同IP下所有redis实例端口不可一致 port 6379 # 开启redis集群 cluster-enabled yes cluster-config-file nodes.conf # 是否需要每个节点都可用,集群才算可用,关闭 # cluster-require-full-coverage no # 集群节点IP地址 # 如果填写没有填宿主机IP,虽然能单机连接正常使用,但是在使用代码连接时,如果有自定义配置,则会报错,初始化失败 cluster-announce-ip 192.168.0.125编写docker-compose
version: '3.8' services: redis-01: image: redis:6.2.2 volumes: - ./redis-01/config/redis.conf:/usr/local/etc/redis/redis.conf - ./redis-01/data:/data ports: - 6371:6371 - 16371:16371 #通讯端口 privileged: true restart: always user: root command: "redis-server /usr/local/etc/redis/redis.conf"执行集群创建命令
#!/bin/bash docker exec -it $(docker ps -f name=redis-01 -q) /bin/bash -c 'redis-cli --cluster create 192.168.0.177:6371 192.168.0.177:6372 192.168.0.177:6373 192.168.0.177:6374 192.168.0.177:6375 192.168.0.177:6376 --cluster-replicas 1 -a gjzz2020'
初始化 Redis 集群
- 执行
cd script/redis命令切换到redis相关脚本目录 - 编辑
redis-cluster.sh文件, 修改redis的 IP 地址为redis集群运行的服务器主机IP - 执行
sh redis-cluster.sh命令, 初始化redis集群 - 初始化过程中需要用户确认, 根据提示同意即可
- 集群初始化成功后会有提示信息, 根据提示信息可判断是否成功